GPT-4o: Un Paso Adelante en la Interacción Humano-Computadora
En la era de la inteligencia artificial, los avances en modelos de lenguaje continúan sorprendiendo y revolucionando la forma en que interactuamos con la tecnología. GPT-4o, la última innovación de OpenAI, marca un hito significativo en este campo, permitiendo una interacción más natural y fluida entre humanos y máquinas.
¿Qué es GPT-4o?
GPT-4o, donde «o» significa «omni», es un modelo de inteligencia artificial diseñado para aceptar entradas de texto, audio, imagen y video, y generar salidas en forma de texto, audio e imagen. Esta capacidad multimodal permite a GPT-4o comprender y responder a una variedad de formatos de manera más eficiente y precisa. Una de las características más destacadas es su capacidad para responder a entradas de audio en tan solo 232 milisegundos, un tiempo de respuesta comparable al de una conversación humana.
Mejoras en el Rendimiento y Costos
En comparación con sus predecesores, GPT-4o no solo iguala el rendimiento de GPT-4 Turbo en inglés y código, sino que también muestra una mejora significativa en el manejo de textos en idiomas no ingleses. Además, es mucho más rápido y un 50% más económico en la API, lo que lo hace accesible para una mayor audiencia y aplicaciones.
Avances en Visión y Audio
GPT-4o sobresale en la comprensión de visión y audio, áreas donde los modelos anteriores tenían limitaciones. Antes de GPT-4o, la interacción por voz con ChatGPT implicaba una latencia considerable debido al uso de múltiples modelos en la conversión de audio a texto y viceversa. GPT-4o elimina estas limitaciones al procesar todas las entradas y salidas con una única red neuronal entrenada de manera integral en texto, visión y audio.
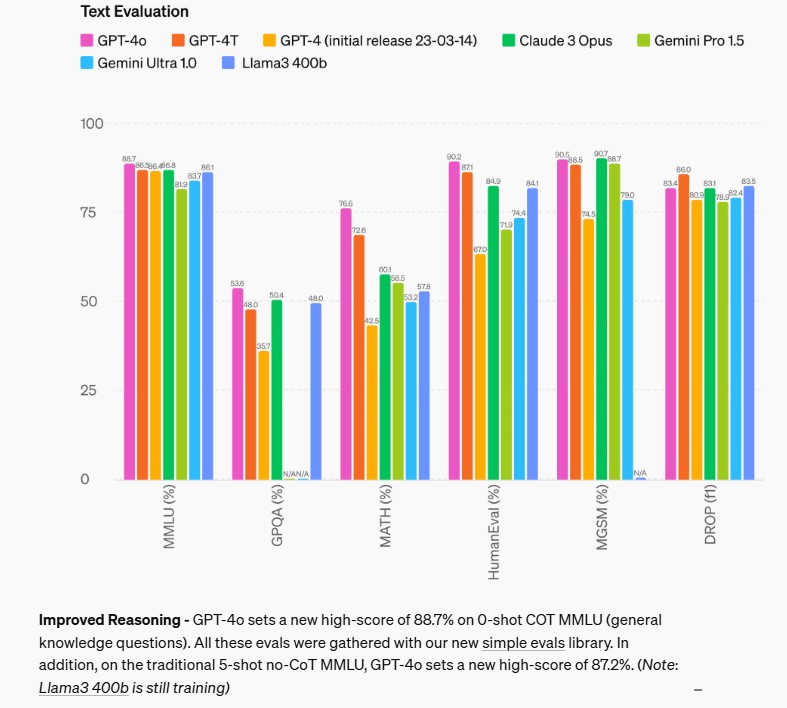
Evaluaciones del Modelo
Según los benchmarks tradicionales, GPT-4o alcanza el nivel de rendimiento de GPT-4 Turbo en inteligencia de texto, razonamiento y codificación, estableciendo nuevos récords en capacidades multilingües, de audio y de visión. En particular, ha logrado una puntuación del 88.7% en el MMLU (Preguntas Generales de Conocimiento) en un entorno de 0-shot COT, superando a otros modelos existentes.